
 mastodon uno admin
mastodon uno admin 
Mark your agendas and save the date: Our annual symposium will be on 19 January 2026 in Leiden!
We are looking forward to our third symposium. Following successful days in Amsterdam and Groningen, we will meet in Leiden for a day filled with presentations, workshops and networking opportunities.


 "
" Listen to the latest episode of our
Listen to the latest episode of our 
 Open Science Bites is a series of short
Open Science Bites is a series of short 




 Research software that never breaks? That’s the idea behind Reusable Execution Environments (REEs)!
Research software that never breaks? That’s the idea behind Reusable Execution Environments (REEs)! April 28, 17:30 CEST
April 28, 17:30 CEST Christoph B. Blessing on REEs for WiKoDa
Christoph B. Blessing on REEs for WiKoDa

 Ukrainian Reproducibility Network (@UARN) is now part of the Global Reproducibility Networks!
Ukrainian Reproducibility Network (@UARN) is now part of the Global Reproducibility Networks! Today’s meeting: action plan, open resources, outreach
Today’s meeting: action plan, open resources, outreach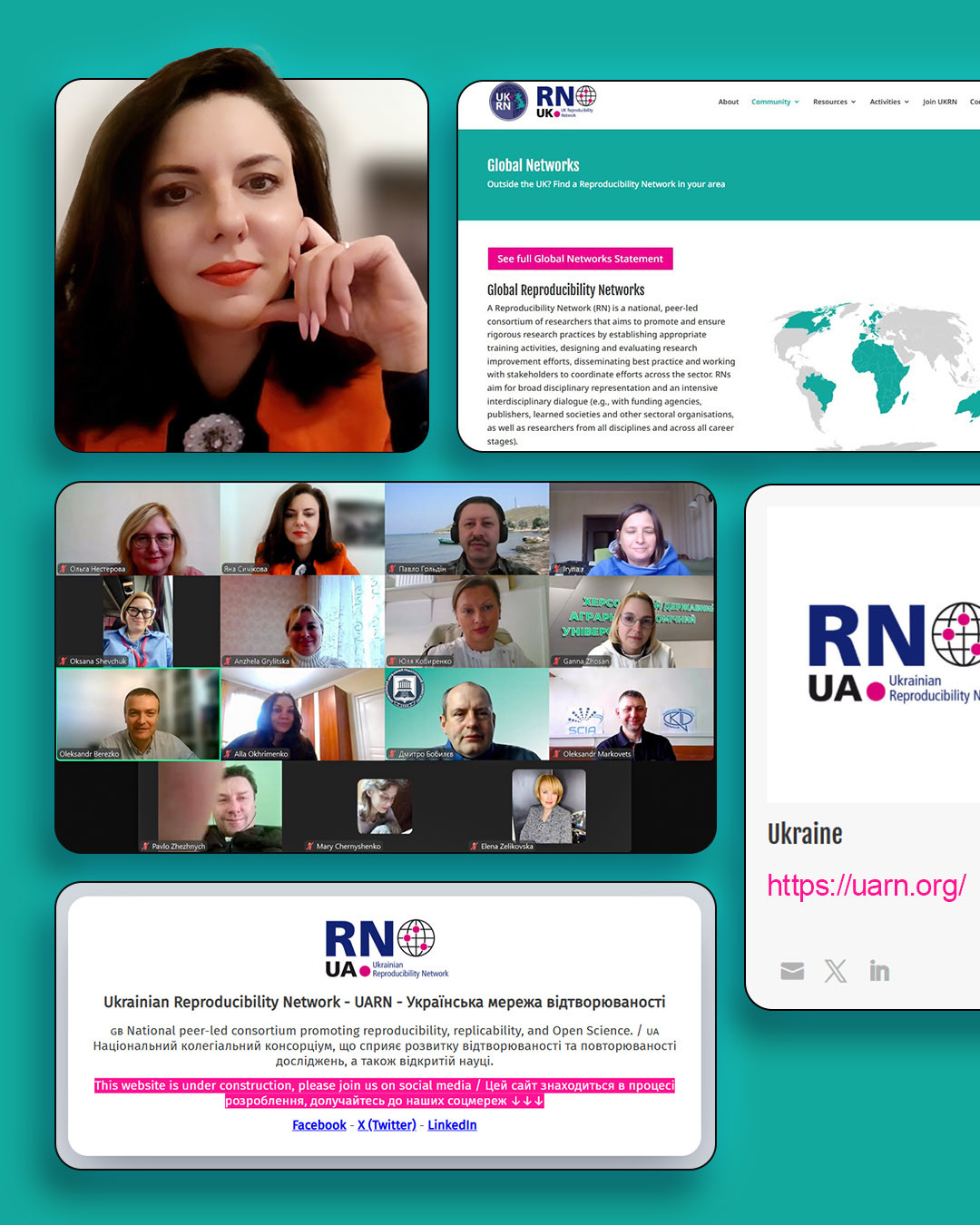








 Huge thanks to the community, organizers & sponsors!
Huge thanks to the community, organizers & sponsors!



 Co-organized by
Co-organized by  Keynotes by
Keynotes by  Workshops by Deborah Schmidt, Ella Bahry & Ulf Tölch
Workshops by Deborah Schmidt, Ella Bahry & Ulf Tölch  Roundtable "Reproducibility in Research Assessment" moderated by
Roundtable "Reproducibility in Research Assessment" moderated by  Thank you everyone for valuable input and engaging discussions!
Thank you everyone for valuable input and engaging discussions! Slides will be published shortly
Slides will be published shortly , Mathijs Vleugel (Helmholtz Open Science Office), Miriam Kip (Berlin Institute of Health at Charité), Sven Rank (Forschungszentrum Jülich), Wolfgang zu Castell (GFZ Helmholtz-Zentrum für Geoforschung)")



 cup.org/41w9d82
cup.org/41w9d82
 You can now explore an analysis inside of a scientific paper!
You can now explore an analysis inside of a scientific paper! Watch now ->
Watch now -> 






 Interested in improving research transparency & reproducibility? Join the Meta-Science Summer School to design & launch a meta-research study!
Interested in improving research transparency & reproducibility? Join the Meta-Science Summer School to design & launch a meta-research study! Co-organized by the
Co-organized by the  Date: 15 - 20 June 2025; Apply by March 21, 2025!
Date: 15 - 20 June 2025; Apply by March 21, 2025! Language: English
Language: English, the German Reproducibility Network (GRN), the META REP Priority Program, iRise and the University of Coimbra EXCELScIOR project ERA chair.")